I am not able to read api-scrip-master.csv file using Panda in Python.
Note: I’ve installed ubuntu on my android tablet using termux (terminal) and all python modules have been installed under virtual environment using -venv.
My coding is as follows:
from dhanhq import dhanhq
import pandas as pd
client_id = “client_id”
access_token = “access_token”
dhan = dhanhq(client_id, access_token)
def get_instrument_token():
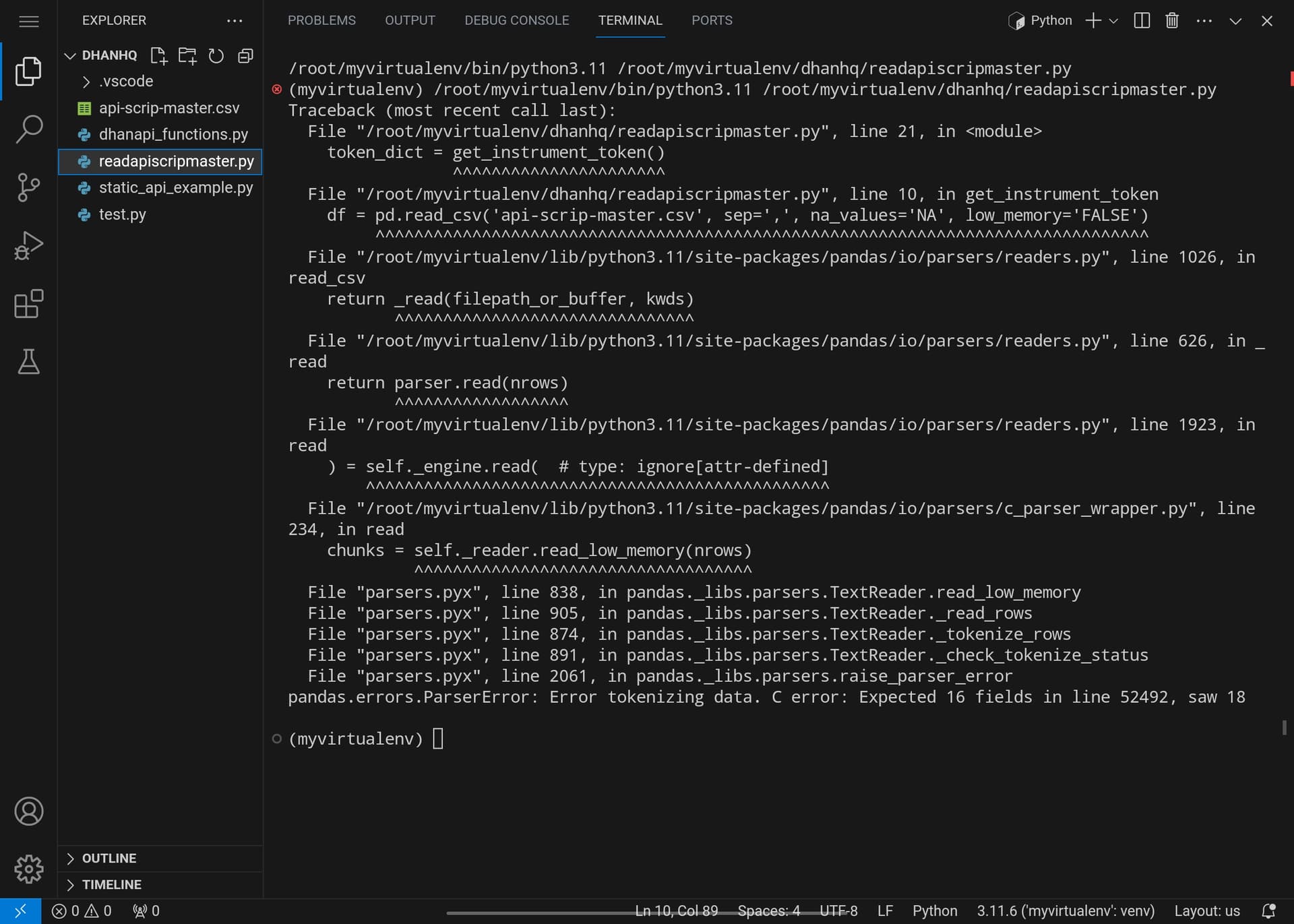
df = pd.read_csv(‘api-scrip-master.csv’, sep=‘,’, na_values=‘NA’, low_memory=‘FALSE’)
data_dict = {}
for index, row in df.iterrows():
trading_symbol = row[‘SEM_TRADING_SYMBOL’]
exm_exch_id = row[‘SEM_EXM_EXCH_ID’]
if trading_symbol not in data_dict :
data_dict[trading_symbol] = {}
data_dict[trading_symbol][exm_exch_id] = row.to_dict()
return data_dict
token_dict = get_instrument_token()
def get_symbol_name(symbol, expiry, strike, strike_type):
instrument = f’{symbol}-{expiry}-{str(strike)}-{strike_type}’
return instrument
#INPUTS
symbol = ‘NIFTY’
expiry = ‘Mar2024’
strike = ‘22300’
strike_type = ‘PE’
instrument = get_symbol_name(symbol, expiry, strike, strike_type)
print(token_dict[instrument][‘NSE’][‘SEM_LOT_UNITS’])
print(token_dict[instrument][‘NSE’][‘SEM_SMST_SECURITY_ID’])
token_dict = get_instrument_token()